How File Paths Work
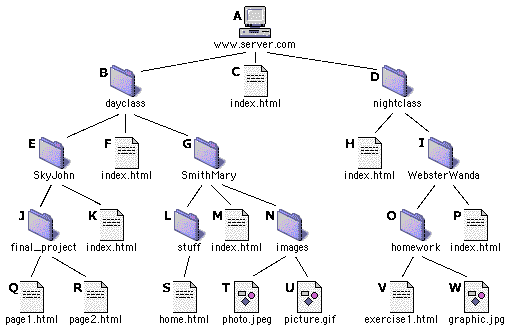
Here is a simplified visual representation of the directory structure, or "tree," of a Web server called www.server.com (A). See below for an alternate visual model of this same file structure.) The server contains two directories (folders), dayclass (B) and nightclass (D), as well as a file called index.html (C) . We speak of items B, C, and D as being at the top level, or "root" level, of the server. (Yes, I know that one would normally think of a root level as being at the bottom instead of the top, but that's the way this jargon works.)
In turn, the dayclass and nightclass directories contain subdirectories and files, and so on "down" the tree. For example, the dayclass (B) directory contains, among other things, the SkyJohn (E) directory, which contains the final_project (J) directory, which contains the Web page page1.html (Q). Going "up" the tree, page1.html is inside final_project, which is inside SkyJohn, which is inside dayclass, which is at the root level of the server.
Relative Paths
If two files are in the same directory tree (this usually means they are on the same server) a relative path can be used to describe the way to link one file to another. A relative path depends on the location of files relative to each other, hence the term "relative." Think of one file as the starting point, the other as the destination, and the relative path as the directions to get from the first file to the second.
If two files are in the same directory, the relative path from one file to
another is simply the file name of the other file. For example, the relative
path from page1.html (Q) to page2.html (R)
is
page2.htm
We say that files in the same directory are at the same "level of heirarchy."
If two files are on the same server but are in different directories, then
more information is needed to describe the relative path from one to the other.
Because the files are at different levels of heirarchy, it is necessary to travel
either "up" or "down" the tree structure to go from one file to the other. Let's
say we want to travel from K to Q. Q
is inside J (the final_project directory), which is inside
E (the SkyJohn directory). K, our starting
point, is also inside E. Starting from inside E,
we need to go into J to get to Q. So the path
from K to Q is
final_project/page1.html
In other words, if we need to go "down" the tree, the names of the directories we travel through are separated by slashes.
What does the path look like if we need to go down through two levels? The
path from F, which is inside B, to Q
is
SkyJohn/final_project/page1.html
The above examples show paths going "down" the file tree. But how
do we descibe a path going "up" the tree? Going up the tree, we use
two dots instead of directory names. For example, ../ means "go
up one level of heirarchy." The path from K to F
is
../index.html
Going up two levels, the path from Q to F
is
../../index.html
Sometimes it is necessary to navigate both up and down a tree to get from one
file to another. In such a case, the relative path from page1.html (Q)
to index.html (M) is
../../SmithMary/index.html
If the two files are on different servers, a relative path cannot be used to describe the way to get from one file to the other. In this case a URL is needed to describe the way to get to the destination.
Uniform Resource Locators (URLs)
A URL (uniform resource locator, or universal resource locator) is a unique
address on the Internet. The URL of a Web page on the Internet would usually
start with "http://" followed by the server name, and then go down
the tree to the destination file. For example, the URL of Q
is:
http://www.server.com/dayclass/SkyJohn/final_project/page1.html
the URL of V is:
http://www.server.com/nightclass/WebsterWanda/homework/exercise1.html
Alternate model of the same file structure